Eu tenho uma instância do postgres onde preciso descobrir quem/o que está se conectando. A versão instalada do postgres é 9.0.1. A instância fica em uma caixa Linux, SUSE, eu acredito. Onde posso procurar se já está registrando isso? Se não for, o que posso ativar? Preciso do nome do host e/ou IP de origem, realmente não preciso de nenhuma outra informação fora disso.
Abaixo está um trecho da minha TRY/CATCHlógica dentro de um procedimento armazenado com tratamento de erros (não incluí todas as DECLAREinstruções). Isso está sendo executado em um procedimento armazenado, no entanto, estou simplesmente testando isso em uma sessão via SSMS (isso afetaria o comportamento?). Eu tropecei neste tópico , mas eu tenho que ir tão longe para simplesmente capturar erros?
BEGIN TRY
DECLARE @sql varchar(1000);
SET @sql = 'select 1/0';
EXEC(@sql);
-- On Error the remaining TRY/CATCH below is compeltely ignored I discovered.
DECLARE @error int;
SET @error = @@error;
IF @error > 0
BEGIN
SET @raisemessage = 'SQL Backup Error: ' + cast(@rc as varchar(10));
RAISERROR (@raisemessage, 16,1);
END
END TRY
BEGIN CATCH
SET @errormessage = ERROR_MESSAGE();
IF @errormessage is null
SET @errormessage = ''
SET @errorstring = @errorstring + 'Database: ' + @name + ' Error: ' + @errormessage + char(10) + char(10);
END CATCH
Alguém pode explicar as deficiências deste bloco TRY/CATCH? Isso não funciona em T-SQL?
Recebi uma conta de domínio específica para lidar com backups de meus administradores de sistema. Estou um pouco confuso, pois nunca recebi uma conta de domínio separada para lidar com backups no passado. Eu ainda quero usar o Agent para lidar com isso, então estou pensando que eles estão pensando o seguinte:
Se você estiver executando o trabalho em uma conta proxy, o proxy deverá ser uma conta de domínio. Adicione a conta à função de servidor sysadmin e conceda a ela controle total do diretório e do compartilhamento de rede.
Então, fiz o que pensei que o descrito acima está descrevendo, adicionei a conta de domínio como login, criei uma credencial e proxy e criei a etapa de trabalho como CmdExec para executar sob o proxy, mas ainda recebo:
Erro do sistema operacional 5 (Acesso negado.).
Não é até que eu dê acesso à conta de serviço que está executando o serviço SQL Server que eu posso fazer backup para esse compartilhamento de rede. Também estou preocupado com restaurações e queria utilizar o Agent para lidar com tarefas de limpeza e mover arquivos para vários diretórios à medida que envelhecem.
Então, não tenho certeza do que está acontecendo aqui, mas acho que a conta de serviço no mínimo precisa de acesso de gravação? Um administrador de sistema disse que estava ciente de alguém fazendo o processo de backup como um "serviço separado", que não entendo muito bem, a menos que seja algo como backup ApexSQL ou algo assim ...
Portanto, determinei que o comportamento errático do meu SQL Server é devido à configuração padrão do .Net SqlClient Data Provider de SET ARITHABORT OFF. Com isso dito, li vários artigos que debatem a melhor maneira de implementar isso. Para mim, eu só quero uma maneira fácil porque o SQL Server está sofrendo e meu ajuste de consulta não transcendeu totalmente o aplicativo (e, obviamente, adicionar o SETem um sp NÃO FUNCIONA).
No brilhante artigo de Erland Sommarskog sobre o assunto, ele basicamente sugere adotar a abordagem segura alterando o aplicativo para emitir SET ARITHABORT ONpara a conexão. No entanto, nesta resposta de uma pergunta dba.stackexchange , Solomon Rutzky oferece uma abordagem em toda a instância e em todo o banco de dados.
Quais ramificações estou perdendo aqui com a configuração dessa instância? Como eu vejo ... como o SSMS tem isso definido ONpor padrão, não vejo nenhum mal em definir isso ONem todo o servidor para todas as conexões. No final das contas, só preciso que esse SQL Server funcione acima de tudo.
Estou vendo 2 planos de consulta muito diferentes entre teste/prod para uma instrução UPDATE que faz parte de um procedimento armazenado. Obviamente, o tamanho da tabela difere (cerca de 10 milhões de linhas de diferença). Basicamente, a diferença está no Prod, estou vendo conjuntos de uma classificação cara seguida de uma atualização de índice (índice nc)
Considerando que em Test, não estou vendo esses conjuntos de operadores! Somente a atualização do índice clusterizado. Verifiquei se os índices NC existem etc. etc. Não consigo descobrir o que está acontecendo?! Já verifiquei índices, o sp, tentei RECOMPILE, valores diferentes para os param's etc. Deve estar faltando alguma coisa, até verifiquei restrições, tudo combina.
Alguma idéia de pensamentos? Eu nunca vi isso antes. O SQL acabou de pegar um plano de execução ruim!?
O UPDATE está estruturado da seguinte forma: UPDATE [nome da tabela] SET [coluna]=123 FROM ...
Os operadores extras no plano de Prod abaixo (menos a atualização do índice clusterizado):

Acho que o .NET Framework 3.5 ainda é necessário para usar o Database Mail com o SQL Server 2017? Como eu tive que incluir isso nas minhas instalações do SQL Server 2016 no Server 2016 há pouco tempo.
Não consegui encontrar uma resposta definitiva pela web, surpreendentemente, talvez ela não seja dita.
Uma pergunta meio boba, mas estou instalando vários SQL Servers para um cliente, mas eles ainda não têm uma conta de serviço de domínio para SQL Server criada para mim. Eles terão um pronto para mim em breve... Realmente faz alguma diferença definir as contas de serviço durante a instalação versus adicioná-las após o fato através do gerenciador de configuração?
Provavelmente mais uma questão de preferência pessoal/economia de tempo, mas eu queria saber se havia algo fora disso. Eu prefiro fazer o máximo durante o processo de instalação em vez de voltar e adicionar a conta de domínio após o fato.
Recentemente, atualizei um SQL Server de 2008 R2 para 2016 e um pacote SSIS no servidor SQL (em msdb) continha tarefas de script ActiveX. Então eu exportei o pacote e peguei o código do ActiveX Script Tasks e o atualizei em Script Tasks regulares, um pacote bem simples. Importei o pacote SSIS de volta para o SQL Server (em msdb) e achei que estava tudo bem. Como o trabalho mostrou, ele foi executado e concluído com sucesso. Mais tarde, sou notificado de que nada aconteceu que o pacote deveria ser feito. Eu até executei o pacote manualmente no Integration Services e ainda nada além dele rodando em cerca de 0,15 segundos (o que esse trabalho deve levar cerca de 5 segundos) e mostrando-o concluído com êxito. O pacote realmente faz o que deveria fazer quando executado a partir de um projeto VS 2015 (com SSDT), mas não faz nada quando está no SQL Server. Alguém já passou por isso!?! Lembro-me de algo sobre o tempo de execução de 32 bits versus o tempo de execução de 64 bits, mas queria verificar aqui primeiro. Alguma solução? Eu até comecei do zero com um novo projeto também.

Tivemos dificuldade em configurar um compartilhamento de FileTable em uma instância do SQL 2014 e depois de desistir de tentar nomeá-lo com o nome da nossa instância, deixamos o nome do compartilhamento como mssqlserver, mas finalmente ficou online, ou seja, online se você clicar com o botão direito do mouse SSMS na tabela FileTable você pode "Explorar o diretório FileTable", no entanto, parece ficar offline aleatoriamente novamente depois de algum tempo e você recebe a mensagem de erro padrão usual:

Então, depois de desabilitar/habilitar magicamente o FILESTREAM no nível do servidor, no nível do banco de dados via t-sql/ssms/configuration manager ele volta de alguma forma, mas eu tenho que mexer com a configuração em todos esses pontos para que ele volte! e parece não haver uma sequência mágica de passos que a faça voltar.
Alguém aí já experimentou isso? Uma reinicialização do serviço/servidor ajudará nisso? Se não, um reparo do servidor sql ajudará?
Trabalho com o SQL Server há algum tempo e entendo os vários problemas que podem ocorrer com o TempDB. Mas, com este último problema, se eu tiver meu problema resolvido corretamente, é possível que uma instrução com um BEGIN TRANSACTION que usa tabelas/objetos tempdb que fica pendente (sem confirmação) possa manter o arquivo LOG tempdb "aberto" e não permitir que o tempdb limpe seu próprio log? Isso faz com que o arquivo de log tempdb seja preenchido e causando problemas no SQL Server. Acho difícil acreditar que não exista algum tipo de proteção no SQL Server que de alguma forma permita que o tempdb LOG não seja afetado Se não, acho isso perturbador…
A seleção de várias colunas de entrada disponíveis e o mapeamento delas para seus respectivos destinos pode ser feito em uma ação!?!?! Em vez de selecionar 1 entrada de cada vez! Eu tentei segurar o controle e a tecla Shift para selecionar vários e arrastá-los, mas apenas aquele em que você clica nas cópias. Isso é uma grande perda de tempo para tabelas que possuem várias colunas e, por qualquer motivo, o SSIS não as mapeia automaticamente, mesmo com os nomes das colunas correspondentes! Estou no SSIS 2008 R2 BTW.
A imagem abaixo é apenas um exemplo para ilustrar o que estou falando, não é meu exemplo pessoal:
(fonte: ggpht.com )
{kind=link}
Alguém pode me dar uma dica sobre o que essa opção realmente faz e o que isso afetaria se eu a desmarcasse repentinamente em um ambiente de produção estabelecido?
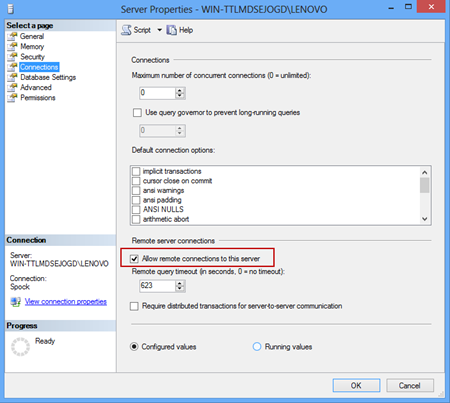
Pesquisei na web por um tempo e não encontrei uma resposta com a qual me sentisse confortável. Estou testando um SQL Server em uma VM que foi apresentada novo disco.
Se a latência do disco for reduzida, a taxa de transferência não deveria aumentar? Existe uma correlação direta entre a latência do disco e a taxa de transferência? Parece que se eu tiver um disco mais rápido, devo ver um aumento na taxa de transferência.