文档坚持认为这ISNULL是一个函数,但COALESCE事实并非如此。具体来说,他们说
ISNULL 函数和 COALESCE 表达式
如果我戴上 Lisp 帽子,我可以将其视为COALESCE一个宏,并且一切都有意义。然而,我在 T-SQL 中从来不需要这样的思考。所以,我必须问。在 T-SQL 中:
- 函数的定义是什么?
- 表达式的定义是什么?
- 如何区分函数和表达式?
文档坚持认为这ISNULL是一个函数,但COALESCE事实并非如此。具体来说,他们说
ISNULL 函数和 COALESCE 表达式
如果我戴上 Lisp 帽子,我可以将其视为COALESCE一个宏,并且一切都有意义。然而,我在 T-SQL 中从来不需要这样的思考。所以,我必须问。在 T-SQL 中:
我想查找 Azure SQL MI 中每个数据库的总已用空间和剩余空间。
为此,在示例中,当我右键单击数据库并选择属性时,我会看到以下示例输出,其中总大小应约为 365 GB:

data_size log_size total_size
TEST_DB 355.69042968750 1.31347656250 357.00390625000
当我运行以下脚本获取数据库中所有表的大小时,表总和约为 500MB,我不知道剩余的 364.5 GB 去哪儿了。
另外,当我再次运行以下解决方案的脚本(https://dba.stackexchange.com/a/339009/289736)时,我看到的数据大小与大约 765MB 左右的数据大小相比要小得多:

我迷失了获取数据库大小的正确方法,因为不同的方法显示不同的大小。如果分配的大小和使用的大小之间存在巨大差距,那么差距从哪里产生?
我设置了一个 SQL Server 分布式可用性组,并且当前已连接到转发器实例。我想知道如何使用 T-SQL 查询适当的 DMV 或目录视图,以确定当前哪个实例充当分布式可用性组中的全局主实例。
我正在寻找可以在转发器实例上执行的 T-SQL 脚本或查询来检索此信息。
任何有关此主题的帮助或指导将不胜感激。先感谢您!
我正在SQL Server Analysis Service 上执行一些DMV 查询SELECT * FROM $system.DISCOVER_SESSIONS,例如. 此查询将返回服务器上所有数据库的数据,因此它并不是真正特定于数据库的。当我通过AdomdConnection连接到服务器时,我没有在连接字符串中指定数据库/目录,并且查询仍然有效。但是我注意到数据库始终与此连接相关联,并且它通常是服务器上可用数据库列表中的第一个数据库。
我的问题是
可能更简短的表述方式是: DMV 查询的性能影响与服务器相关还是与数据库相关?
以下答案(对所有数据库中的所有表执行“sp_spaceused”)对sp_spaceused所有数据库中的所有表执行解决方案。
相反,我只能对所有数据库执行它吗?
我可以使用以下脚本查看所有数据库的结果,但如果可能的话,我想在单个 Excel 表中查看结果,如链接的答案:
DECLARE @DatabaseName NVARCHAR(255)
DECLARE @SqlQuery NVARCHAR(MAX)
-- Declare a cursor to loop through all databases
DECLARE database_cursor CURSOR FOR
SELECT name
FROM sys.databases
WHERE state_desc = 'ONLINE' -- Filter out offline databases if needed
-- Open the cursor
OPEN database_cursor
-- Fetch the first database name from the cursor
FETCH NEXT FROM database_cursor INTO @DatabaseName
-- Start looping through all databases
WHILE @@FETCH_STATUS = 0
BEGIN
-- Build the dynamic SQL query to switch database context and execute the query
SET @SqlQuery = 'USE [' + @DatabaseName + ']; EXEC sp_spaceused @oneresultset = 1'
-- Execute the dynamic SQL query
EXEC sp_executesql @SqlQuery
-- Fetch the next database name from the cursor
FETCH NEXT FROM database_cursor INTO @DatabaseName
END
-- Close and deallocate the cursor
CLOSE database_cursor
DEALLOCATE database_cursor
示例 excel-view 输出,我可以轻松复制所有行并将其作为整体粘贴到 excel 文件中:

请教三个问题:
我们能否拥有跨 3 个 WSFC 集群(即跨越 3 个 AG)的单个 DAG?
如果是这样,是否可以对其进行配置,使两个 AG 位于同一 Active Directory 域中,而第三个 AG 位于不同的 AD 域中?
如果不建议跨 3 个 AG 配置单个 DAG,是否可以跨两个不同 AD 域中的两个 AG 配置一个 DAG?
谢谢
Microsoft 维护着一份不良 DLL 列表。这是该列表中的一项(强调我的)
UMPPC*.DLL 和 SCRIPTCONTROL*.DLL
如果您为 CrowdStrike 防病毒/端点保护程序启用其他用户模式数据防护设置,这些 DLL 文件将加载到 SQL Server 相关进程的地址空间中。当 SQL Server 代理在执行作业时尝试创建新进程时,您可能会注意到失败。尝试启动 SQL Server Management Studio 时可能会遇到失败。您可能还会看到 SQL Server 无法启动 SQLDumper.exe 来生成内存转储。我们建议您联系 Crowdstrike 支持并提供与您的问题相关的信息,并询问是否有可用的修复程序。
我使用的是 SQL Server 2019 机器,并且有许多 UMPPC*.DLL 和 SCRIPTCONTROL*.DLL 文件。我正在考虑使用 SQL Server 代理来触发一些 SSISDB 包。但是,我不确定如何检查这些 DLL 是否引起问题。这给了我我的问题:当 UMPPC .DLL 和 SCRIPTCONTROL .DLL 触发 SSISDB 包时,SQL Server 代理中会导致出现哪些确切的错误消息?
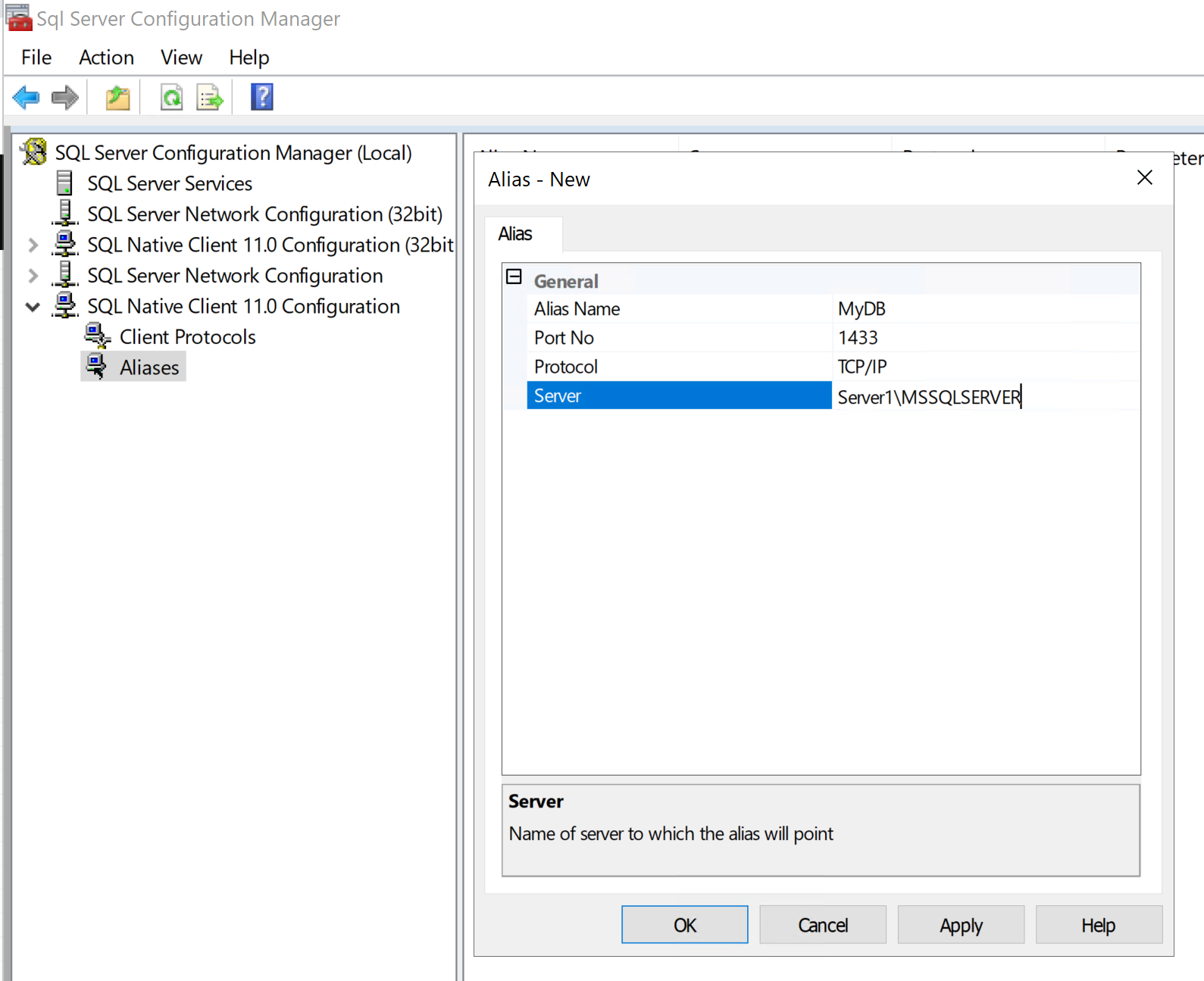
我们有一台服务器运行默认的单个 MSSQL 作为命名实例(名为 MyDB)
我们必须重建服务器,具有相同的 dns 名称
他们在上面安装了 MSSQL 并将旧数据库恢复到其中
但是当他们安装 MSSQL 时,他们使用了默认实例名称
所以现在 Server1\MSSQLSERVER 不再是 Server1\MyDB,而且我们的很多旧东西都坏了
我想在 Server1 的 Sql Server 配置管理器中添加一个别名,它将名称 MyDB 指向 MSSQLSERVER 默认实例。我无法使其正常工作,可能是因为它使用相同的端口或者我没有正确配置它。
我应该在创建别名时使用哪些设置来让我的设置识别旧实例名称并将其重定向到新实例。
我有一个经典的间隙和岛屿问题,我需要总计最新记录中最早的日期中的第一个间隙的时间
查看Find Consecutive Date in SQL using 2 date columns,这为我的问题提供了一个非常简洁的解决方案,除了它不适用于 sql server,存在语法错误。
有人有适用于 sql server 的等效解决方案吗?
数据是这样的
| 参考文献 | TNCY-启动 | TNCY-END |
|---|---|---|
| 1 | 2022-08-22 | 2024-04-22 |
| 1 | 2019-04-29 | 2022-08-21 |
| 1 | 2017-06-26 | 2019-04-28 |
| 1 | 2009-06-29 | 2010-01-31 |
| 2 | 2020-07-13 | 无效的 |
| 2 | 2020-05-18 | 2020-07-12 |
| 2 | 2020-01-13 | 2020-05-17 |
| 2 | 2010-12-06 | 2016-08-28 |
| 2 | 2003-09-29 | 2009-06-01 |
| 3 | 2019-03-25 | 无效的 |
| 4 | 2022-08-22 | 无效的 |
| 4 | 2019-04-29 | 2022-08-21 |
| 4 | 2017-06-26 | 2019-04-28 |
| 4 | 2009-06-29 | 2010-01-31 |
create table #test ([PERSON-REF] INT,
[TNCY-START] DATE,
[TNCY-END] DATE);
INSERT INTO #test VALUES
('1', '2022-08-22 00:00:00.000', '2024-04-22 00:00:00.000'),
('1', '2019-04-29 00:00:00.000', '2022-08-21 00:00:00.000'),
('1', '2017-06-26 00:00:00.000', '2019-04-28 00:00:00.000'),
('1', '2009-06-29 00:00:00.000', '2010-01-31 00:00:00.000'),
('2', '2020-07-13 00:00:00.000', null),
('2', '2020-05-18 00:00:00.000', '2020-07-12 00:00:00.000'),
('2', '2020-01-13 00:00:00.000', '2020-05-17 00:00:00.000'),
('2', '2010-12-06 00:00:00.000', '2016-08-28 00:00:00.000'),
('2', '2003-09-29 00:00:00.000', '2009-06-01 00:00:00.000'),
('3', '2019-03-25 00:00:00.000', NULL),
('4', '2022-08-22 00:00:00.000', NULL),
('4', '2019-04-29 00:00:00.000', '2022-08-21 00:00:00.000'),
('4', '2017-06-26 00:00:00.000', '2019-04-28 00:00:00.000'),
('4', '2009-06-29 00:00:00.000', '2010-01-31 00:00:00.000')
SELECT * FROM #test;
我想最终得到每个人引用的一行,其中包含人引用、间隙后的记录数、间隙后的开始日期、最晚结束日期(或空)、之间的天数。
例如,假设英国日期格式并将 null 作为今天
| 参考文献 | 租约数量 | 第一个 TNCY 启动 | 最后一个 TNCY 结束 | 总租赁天数 |
|---|---|---|---|---|
| 1 | 3 | 2017-06-26 | 2024-04-22 | 2492 |
| 2 | 3 | 2020-01-13 | 无效的 | 第1562章 |
| 3 | 1 | 2019-03-25 | 无效的 | 1866年 |
| 4 | 3 | 2017-06-26 | 无效的 | 2493 |
感谢任何人可以提供的帮助
我已在装有 Windows Server 2022 的 EC2 实例上安装了 SQL Server 2022 Developer Edition,并安装了最新的累积更新 (16.0.4115.5)。当我运行 DBCC TRACESTATUS 时,有 39 个全局跟踪标志打开,但我无法在任何地方找到其中任何一个的信息,例如 4511。没有跟踪标志作为启动参数。
在安装时,我选择全文索引和 Polybase 作为附加功能。
如果我关闭所有跟踪标志并重新启动服务器,那么它们会自动重新打开。
这些跟踪标志是什么?累积更新的一部分?为什么我找不到有关其中任何一个的信息?