我想知道制作表示另一个表的行子集的表的惯用方式,或者至少是一种可行的方式。这是通过有效地存储和查找这些子集来实现的。
例如,医疗环境:您有一个 Patients 表和一个 Allergies 表。患者和过敏症之间存在多对多关系——因此关系数据库模式的常用方法是创建一个桥接表,包含两列:患者键和过敏键。
这是一个 ER 图,其中桥梁链接到患者和过敏:
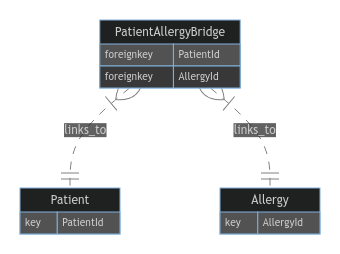
但该解决方案空间效率低下,并且不支持查找具有给定过敏集合的一组患者,因为每个对 A、B 和 C 过敏的患者在桥接表中都有自己的三行。
我想要一个代表过敏子集的表格。因此,例如,我们在桥/子集表中有一种表示“对 A、B 和 C 过敏”:
AllergySubset
SubsetKey | AllergyId
foo | A
foo | B
foo | C
etc etc | other ids
然后,每个对组合 A、B 和 C 过敏的患者都将链接到“foo”。该模式反转了患者与桥接/子集表之间的链接:
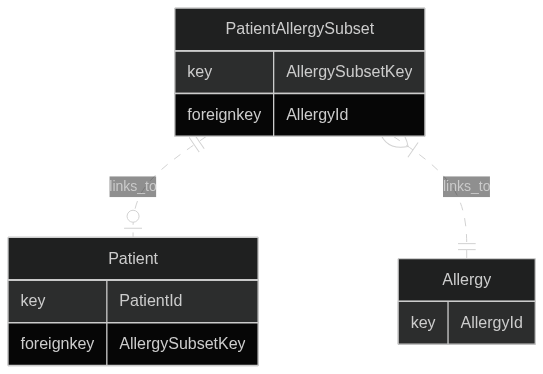
我的问题是:如何查找子集?
给定一个对 B、C 和 E 过敏的患者,如果子集表中已经有一个 AllergySubsetKey,我该如何确定?
或者,等效地:给定过敏 B、C 和 E,如果我知道子集键,我可以找到所有对该组合过敏的患者。我如何找到那把钥匙?
设计此模式的惯用方法是什么?
您可以使用关系除法来进行此类查找。
例如,要查找特定项目列表的子集键,首先将它们放入表变量或临时表中:
要查找包含所有这些过敏和任何其他过敏的子集键,只需删除
HAVING.